4.6 Test di indipendenza in una tabella a doppia entrata
Nella sezione conclusiva di questo capitolo presentiamo un ultimo test che in un certo senso estende il test di adattamento presentato nella sezione precedente al caso di un vettore di due variabili aleatorie discrete, anche se la distribuzione teorica con cui quella empirica viene confrontata è relativa ad una situazione particolare, quella di indipendenza statistica delle due variabili (ipotesi nulla).
Radiant permette di effettuare il test di indipendenza in una tabella a doppia entrata attraverso il comando Basics \(\rightarrow\) Cross-tabs. Le informazioni che dobbiamo fornire nella relativa schermata sono:
- il nome delle variabili che contengono i dati su cui vogliamo effettuare il test di indipendenza (due box successivi, entrambi denominati
Select a categorical variable; consigliamo di selezionare la variabile di riga nel primo box e quella di colonna nel secondo) - il tipo di output da mostrare, ovvero le frequenze osservate (
Observed), quelle attese sotto l’ipotesi nulla di indipendenza (Expected), i contributi al calcolo dell’indice \(\chi^2\) di ogni cella della tabella (Chi-squared), le radici quadrate dei medesimi contributi (Deviation std.), le frequenze condizionate date le righe, quelle condizionate date le colonne o quelle congiunte relative (rispettivamenteRow percentages,Column percentageseTable percentages).
Le Figure 4.9 e 4.10 riportano l’output relativo al test di indipendenza tra le variabili MasterPhd e WideIndustry.
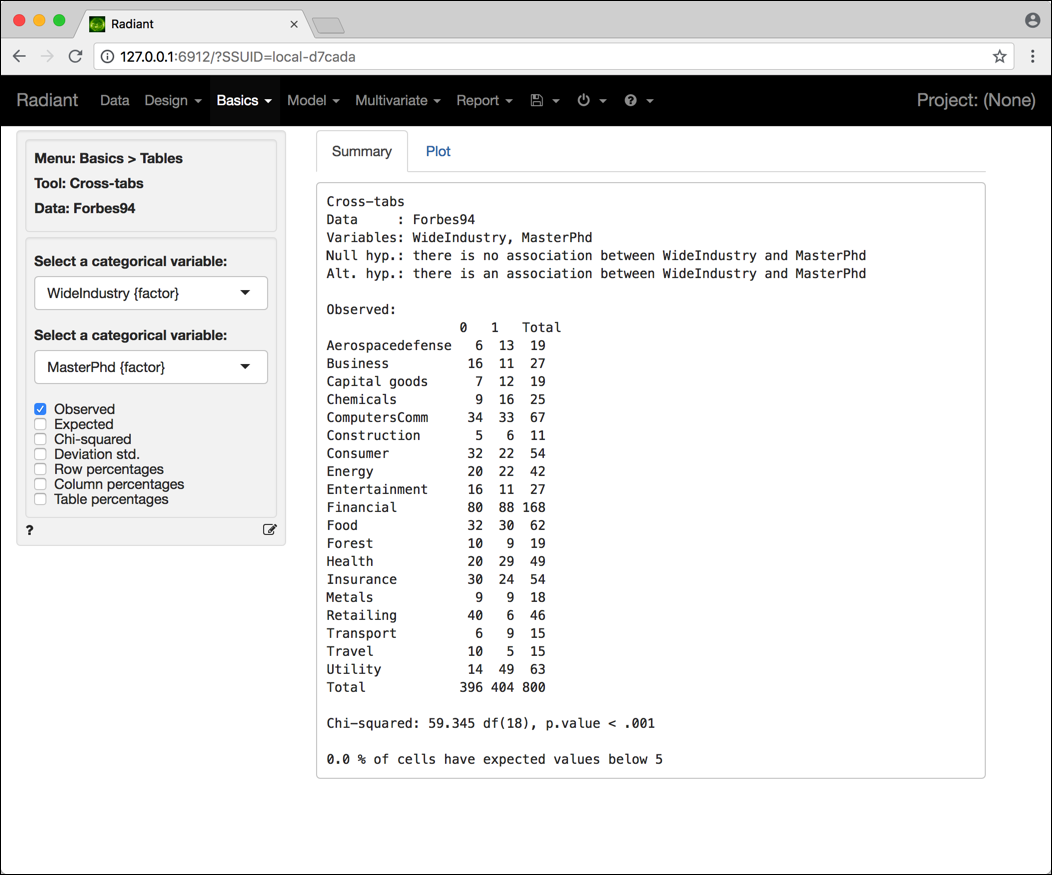
Figura 4.9: Schermata Radiant per il test di indipendenza (frequenze osservate).
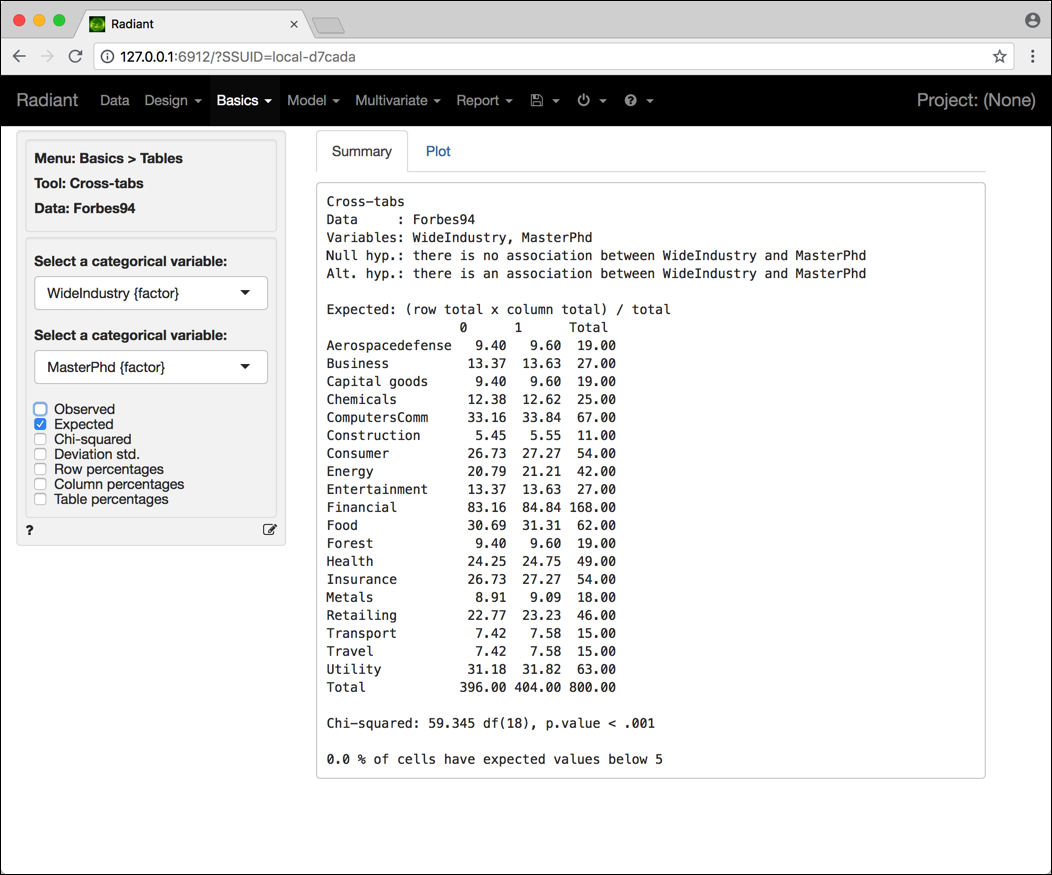
Figura 4.10: Schermata Radiant per il test di indipendenza (frequenze attese).
Il p-value del test riportato nell’output (< .001) permette di concludere che sembra esserci sufficiente evidenza empirica a sfavore dell’ipotesi di indipendenza tra le due variabili. In altre parole, possiamo concludere che la proporzione di CEO con un Master o un PhD dipenda in qualche modo dal settore in cui l’azienda opera (per averne conferma, provate a dare un’occhiata alle frequenze condizionate date le righe).
Anche per il test di indipendenza Radiant riporta nell’output una valutazione delle ipotesi su cui è basato il test. Per l’esempio precedente, infatti, riporta che
0.0 \% of cells have expected values below 5,
quindi l’approssimazione sulla base della quale il p-value è calcolato si può ritenere accettabile.
Una piccola nota tecnica sul p-value riportato in output: quando una o più delle frequenze attese sono piccole, ovvero pari a 5 o meno, Radiant procede al calcolo del p-value usando un metodo di simulazione. Questi casi sono segnalati nell’output attraverso la frase p.value for chi-squared statistics obtained using simulation (2,000 replicates). Questo valore del p-value non corrisponde a quello che otterremmo con la distribuzione chi-quadrato, ma normalmente non dovrebbe discostarsi di molto.